0898-08980898 13876453617

0898-08980898 13876453617
粗暴一点的看法的话:感觉就像,一上一下,强迫你的目标函数长得像一个二次函数.
如果是L-Lipschitz的,就有了一个二次函数的上界:
如果是 -strongly convex的,就有了一个二次函数的下界:
画个示意图,大概长这个样子:
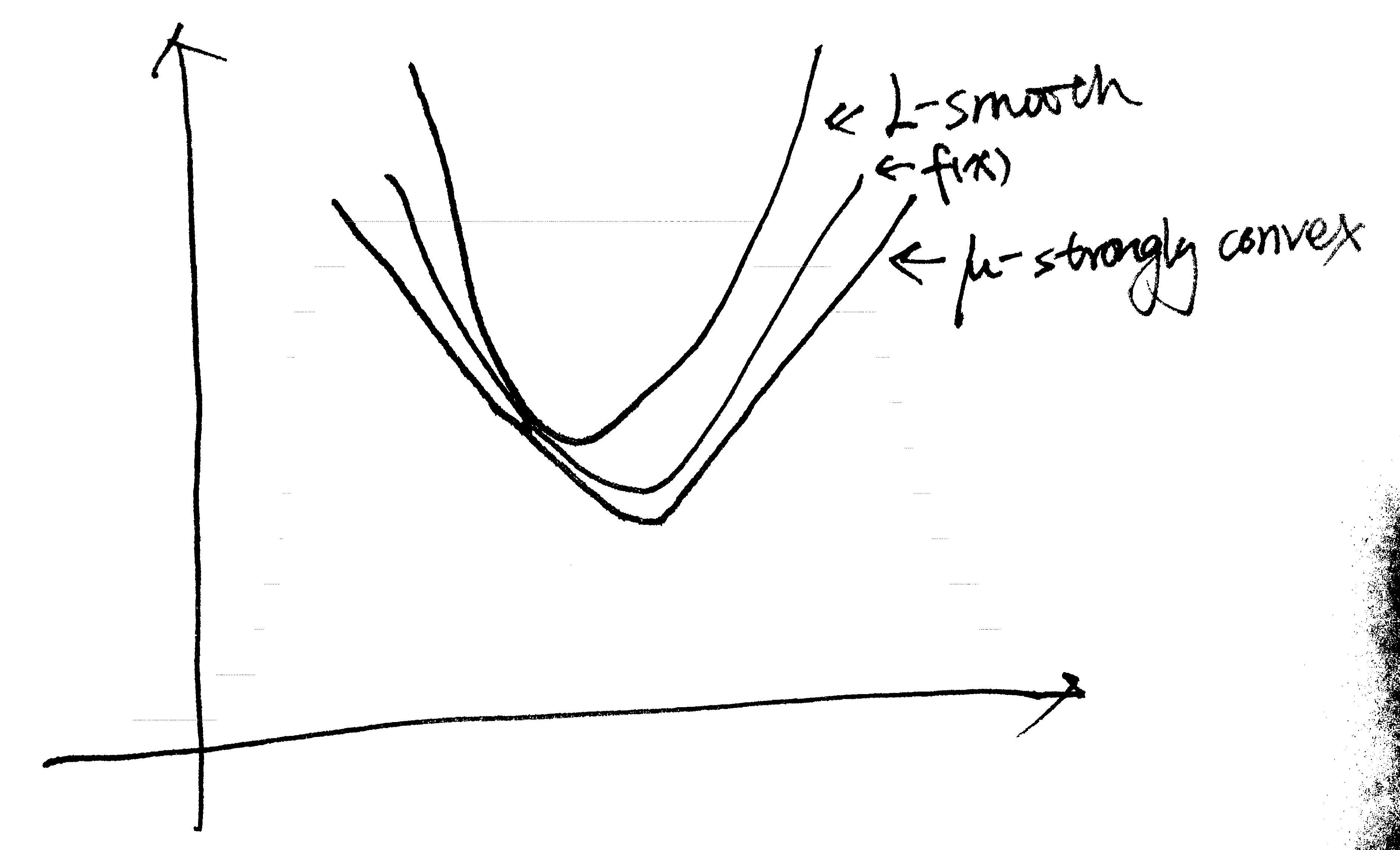
由于被迫长成一个二次函数的样子,于是很多算法在 -strongly convex + L-Lipschiz下都有比较好的表现。
------------------------------------------------------------------------
最后欢迎关注我 @Zeap和我的专栏非凸优化学习之路哇,会写写关于nonconvex optimization的一些基本概念的介绍和自己的理解, 希望对新手会有些帮助吧, 里面的文章有:
Zeap:非凸优化基石:Lipschitz Condition
潘润琦:非凸优化的基石2:Regularity Condition
Zeap:如何理解非凸优化极值条件: 梯度=0 & 二阶导> 0?
证明收敛率需要这些条件,另外L-光滑和1/L-强凸有共轭对应关系。
-smooth中的
,和
-strongly convex中的
这一对CP,如果函数是二次可微的,可以认为它们就等同于函数Hessian矩阵的最大和最小奇异值的上界和下界,也就可以被看作梯度的最大变化速度和最小变化速度。由于SGD实在是一个短视的算法,每一步虽然也是在求解二阶近似,但都把Hessian暴力换成identity matrix了,这么说就明白了,梯度的变化率范围越小,在做GD step的时候越可控,由此反映在了GD的收敛性能上,具体可见这个答案~
这些很大程度是为了证明算法收敛性和收敛率而假设的。
一个简单的应用是,在这些条件下, accelerated proximal gradient (APG)等一阶算法可以有复杂度结果(O(1/k^2)).
当没有这些条件时, 分析起来会很难,比如如果没有这两个条件,大家又转头去考虑类似 自洽(self-concordant) 函数。

Copyright © 2012-2018 开丰娱乐-开丰注册登录绿色站 版权所有 琼ICP备xxxxxxxx号
电话:0898-08980898 手机:13876453617 地址:海南省海口市




 在线咨询
在线咨询