0898-08980898 13876453617

0898-08980898 13876453617
本文在 @蓝色 的文章基础上补充修改蓝色:手把手带你遨游TVM
原文链接:
人工智能无疑是目前风口浪尖的话题,大部分提到人工智能都关注在了算法,然而若要让人工智能落脚在实际应用中,工程化是至关重要的。本文脉络如下图所示,帮助大家理解。

模型的生产过程分为两步:Training部署、Inference部署。
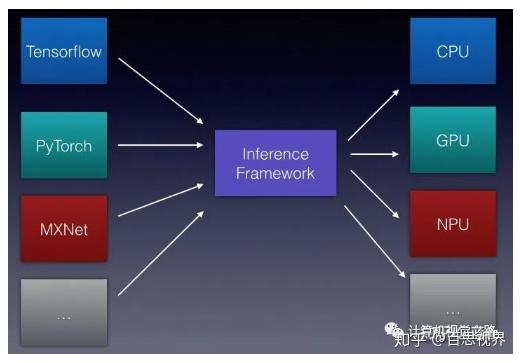
但是,想在这多种多样的设备中,都保持一个高效的Inference性能,其实是一件很有挑战的事情。
要达到模型能够在不同设备中都保持高效的Inference性能的目标是很不容易的。各种硬件设备的特性千差万别,如何保持一个统一的高效执行,是一个非常难做到的事情。而各大硬件厂商针对这样的情况都推出了自己的Inference 框架,相比TensorFlow等这样的框架孱弱的Inference性能,各大设备厂商的Inference框架性能都比较不错,如Intel的OpenVINO,ARM的ARM NN,NV的TensorRT等。但是这又带来更多的问题:
其实对于业务方来说,需要一个统一的Inference框架,然后在业务场景的各种硬件设备都能高效的运行,使用体验一致,只需要简单的根据硬件环境来配置相应的参数就好了。
各个硬件厂商针对自己硬件平台的Inference框架,使模型仅在自己的平台高效的运行。但是对于业务方(用户)来说,还是没很好的解决如何使自己的模型能在不同的硬件平台高效的运行的问题。
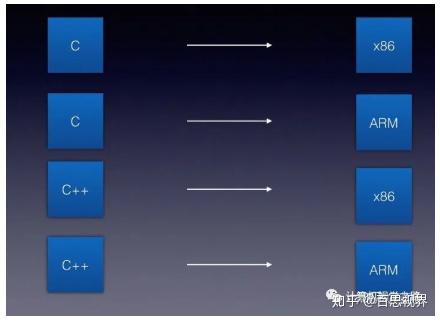
问题的解决可以类比编程语言。曾经出现了很多种编程语言,有很多种硬件,历史上最开始也是一种语言对应一种硬件,从而造成编译器的维护困难与爆炸。如下图所示。
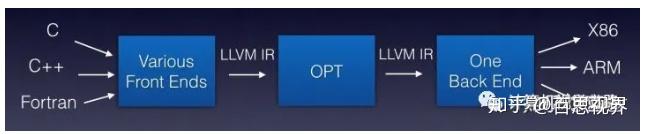
而编译器解决了这个问题,其具体解决办法是这样的:抽象出编译器前端,编译器中端,编译器后端等概念,引入IR (Intermediate Representation)
类似如下图所示的架构:
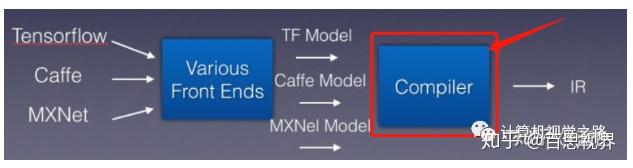
其实对于Inference框架也是类似的道理,只不过将编程语言,换成了不同的训练框架,相应的架构如下图所示:

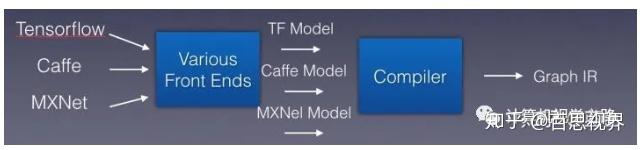
把各种模型抽象看成各种编程语言,则需要引入一个新的编译器,如下图中红框(Compiler)所示,负责把这些不同框架的模型识别,然后吐出IR。
深度学习的模型构成是计算图,因此,可以将IR称为Graph IR。则Compiler的作用是输入不同训练框架训练的算子与模型,将其编译成Graph IR。
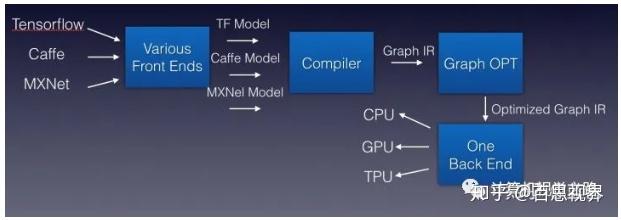
最后我们只需要实现对Graph IR的优化,即实现相应算子的优化,即可以将优化后的模型部署到不同的平台,最终结构如下图所示。
接下来就是实现的问题了:如何实现这样一个编译优化器,可以将不同训练框架训练得到的模型优化到不同硬件平台去高效运行?答案就是:NNVM compiler。如下图所示。
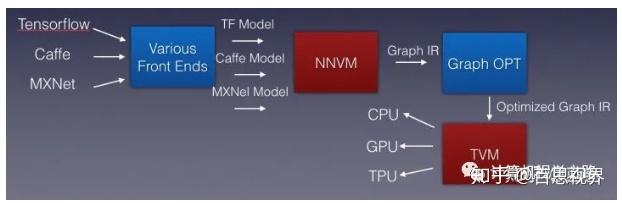
NNVM compiler基于此前发布的TVM堆栈中的两个组件:NNVM用于生成计算图,TVM用于映射张量运算。
让我们给出一副更详尽,更漂亮的一张图:
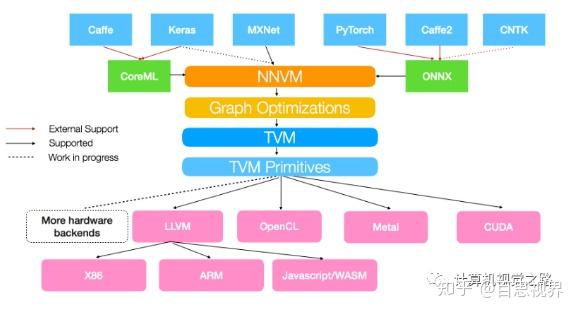
NNVM compiler是亚马逊和华盛顿大学合作发布的开源端到端深度学习编译器,支持将包括mxnet,pytorch,caffe2,coreml等在内的深度学习模型编译部署到硬件上并提供多级别联合优化。速度更快,部署更加轻量级。支持包括树莓派,FPGA板卡,服务器和各种移动式设备和cuda,opencl,metal,javascript以及其它各种后端。
NNVM compiler可以将前端框架中的算子直接编译到硬件后端,能在高层图中间表示(IR)中表示和优化普通的深度学习算子,也能为不同的硬件后端转换计算图、最小化内存占用、优化数据分布、融合计算模式。
读完这篇文章,我相信,当大家处在将深度学习inference模型部署在不同硬件平台的泥沼当中时,现在已经有了自己的解决方案。

Copyright © 2012-2018 开丰娱乐-开丰注册登录绿色站 版权所有 琼ICP备xxxxxxxx号
电话:0898-08980898 手机:13876453617 地址:海南省海口市




 在线咨询
在线咨询