0898-08980898 13876453617

0898-08980898 13876453617
如题,我是一个神经网络方向的初学者,想知道应该如何【系统】地分析性能优化方面的问题?
准确度不高,首先要分清是训练集准确度不高,还是测试集准确度不高。
如果两者都不高,而且没有明显下降趋势,可能需要重新选取模型。比如增加神经网络的层数和单元数,调整学习率等超参数。
如果有下降趋势,那么可以考虑增加训练时间再看看效果。或者使用更高效的优化算法(Momentum,Adam等),使用batch norm,改换激活函数(如Relu),提高训练速度。
如果是仅仅测试集不高,可能存在过拟合。那么这时候需要从两方面考虑优化使其具有广泛性:更多的数据,提前停止,或者正则化方法(比如L2 ,dropout等)。
希望能帮到您
数据,模型,损失。
数据可能存在燥点或严重类别不平衡,这是应对数据筛选。模型是能提点的更大关键,比如vgg19和res50肯定存在性能差异,但在不同任务中谁优谁劣要实际考究,一般是越深的网络效果越好(没有梯度消失,过拟合等问题)。最后是损失,不同损失的优化目标直接不同,会严重影响效果,比如分类常用交叉熵,检索常用度量损失triplet loss,center loss, arc face等,还有目标检测领域提出的环节类别不平衡的focal loss等。最后不同优化器也有差别,如adam和sgd优化结果也不同,超参也有影响。
深夜睡不着强答
假定这个准确率不高指的是在测试集上泛化能力不强。按顺序泛泛而谈理一下我个人的思路
1,检查模型代码
首先你得保证你的模型代码与你理解中的模型长得一个样。限于数值计算问题,可以接受一个粗略近似解决方案,但是起码得靠谱,要不然嘴里说着a+b手上写着a*b,神仙都救不了,起码得写个a-(-b)吧
2,选取合适的baseline
在确保模型代码大致正确的情况下,选取合适的baseline,和当前模型做对比。这个baseline可以是其他论文在当前数据集上的结果,也可以是领域内大家认可的通用模型在当前数据集上的结果(e.g., BERT@ NLP)
另外这个baseline需要合适,比如你的模型是RNN-based的,那你选一个BERT当baseline就纯属自己搞自己。同理你的模型是RoBERTa,那你选一个BiLSTM的当baseline也是在搞事情。具体选择方法请参见高中生物实验设计的“控制变量法”“对比实验法”等
3,与baseline做比较
如果你的模型效果比baseline高,那么说明大概率不是模型的问题,而是数据集的问题,可能这个数据集就是非常难刷(或者说这一类模型不适合用来刷这个数据集,这时候就应该从别的角度来考虑问题了,用新的思路来设计新的模型)
如果你的模型效果比baseline差,这一般来说有两种可能(假定你选取的baseline是合适的,而且在跑baseline的过程中没啥毛病……一般来说连baseline都跑不出来的情况下个人觉得暂时不是很配讨论你这个模型的效果)
i. 回到代码端,可能是你的训练测试代码有问题,包括但不限于你选择了较差的超参(超参包括learning rate,optimizor,batch size,schedule等等),训练步骤写错了,评估的metric写错了,中间梯度爆炸或者消失了,跑的epoch过多或过少,没有加或者加错了weight decay,等等等等
ii. 回到模型端,如果你的目标模型是在baseline的基础上加了一大堆花里胡哨的,有可能是死于花里胡哨,试着一步步把这些东西去掉,还原成baseline的样子(相当于反向做ablation study)然后分析原因(这里面的问题可能有代码实现上的,也有可能有数学理论上的)。如果不是,那可以挑一些bad case出来单独分析一下。
4,重构代码
正如重启专治不服一样,重构在很多情况下非常有奇效(个人亲测)
把之前写的代码完全忘记,重新写一遍,有时候会发现不知道为什么突然就没毛病了(至于说两次写会写成一毛一样的……我觉得要么就是在疯狂调包没有什么自我发挥的空间,要么就是……反正这一种这里实在没什么意见可以给了)
5,得出结论
在前面4步中途穿插若干次与他人的讨论/头脑风暴,然后都搞不定的情况下,这里个人建议给这个模型判死刑(扶了半天扶不起阿斗只能假装自己跟相父一样鞠躬尽瘁死而后已了让这个模型自生自灭去吧)
至于为什么类似的idea自己做了永远不work人家做了永远发paper……我觉得真相只有一个……这就是命……(不能光看人家发论文不看人家在背后堆了多少tricks掉了多少根头发嘛对吧。炼丹炼丹,哪怕用一样的炉一样的料一样的火候,也有人炼出仙丹有人炼出诺贝尔嘛,看开点就好了)
以上主要是指的从发paper的角度
要是从工业的角度来思考,还有一个很重要的点叫做“清洗数据”
最近刚好也在考虑AI框架(MindSpore)如何帮助模型开发者提升精度调优效率的问题,总结了一些思路供参考:
模型的准确率不高,模型的metrics达不到预期,常见的原因有以下几方面:
1、数据集问题
2、数据处理算法设计和实现问题
3、算法设计和实现问题
4、超参设置问题
5、普通python编程错误
6、环境问题
分析模型准确率不高的问题,就是要分析数据集、数据处理、算法设计、算法实现等方面是否存在问题。这一过程是有章可循的,建议参考下面五步,逐步定位模型表现问题:
第一步 检查代码和超参
第二步 检查模型结构
第三步 检查输入数据
第四步 检查loss曲线
第五步 检查准确率是否达到预期
代码是准确率问题的重要源头,检查代码重在对脚本和代码做检查,力争在源头发现问题;模型脚本体现了AI模型在AI框架上的表达和映射,检查模型脚本重在检查脚本表达和算法工程师的设计是否一致;有的问题要到动态的训练过程中才会发现,检查输入数据和loss曲线正是将代码和动态训练现象结合进行检查;检查准确率是否达到预期则是对整体分析过程的重新审视。此外,充分准备,熟悉模型也是很重要的。
具体这五步怎么做,可以参加下面链接:
金雪锋:AI框架如何帮助开发者提升精度调优效率按道理讲,在建立人工神经网络模型的时候,首先要分析数据的特点,然后根据数据所存在的特点,针对性地优化、设计人工神经网络的结构。

同时,将一些经典的信号分析方法,作为可训练的步骤,融入人工神经网络的网络结构之中,也是一种典型的创新思路。
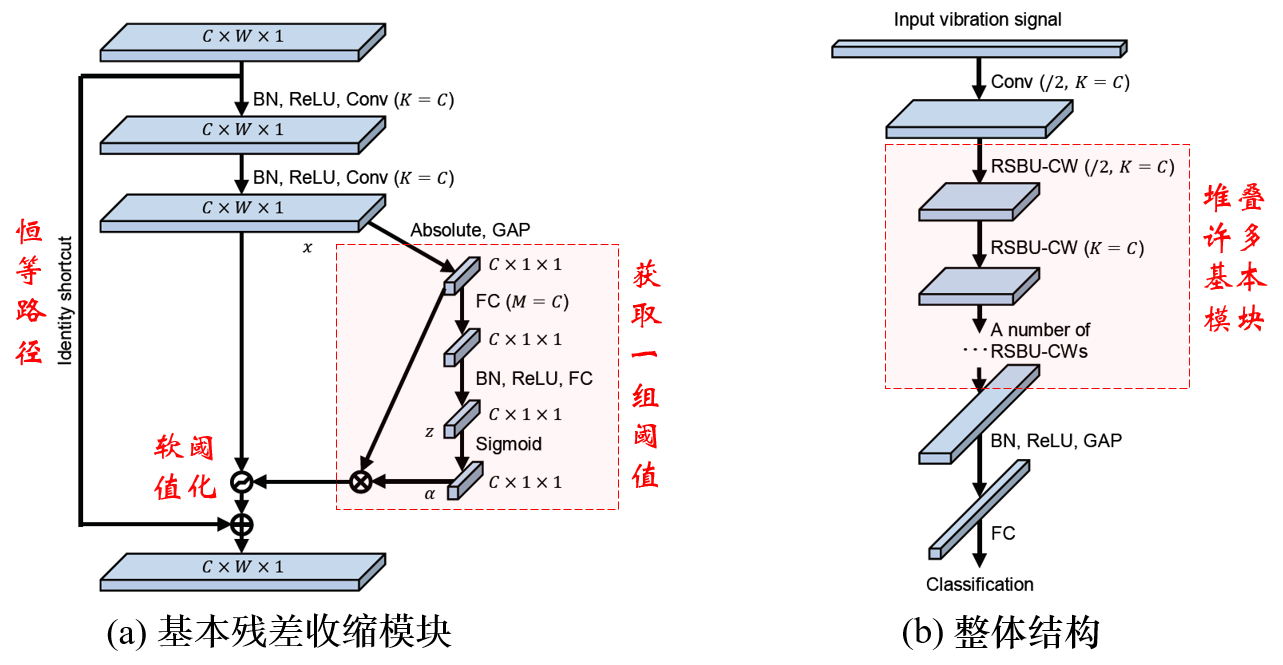
例如,如果数据含有大量噪声,那么可以考虑残差收缩网络,在网络结构中加入软阈值函数,参考10分钟看懂深度残差收缩网络 - 翼下之峰 - 博客园 。
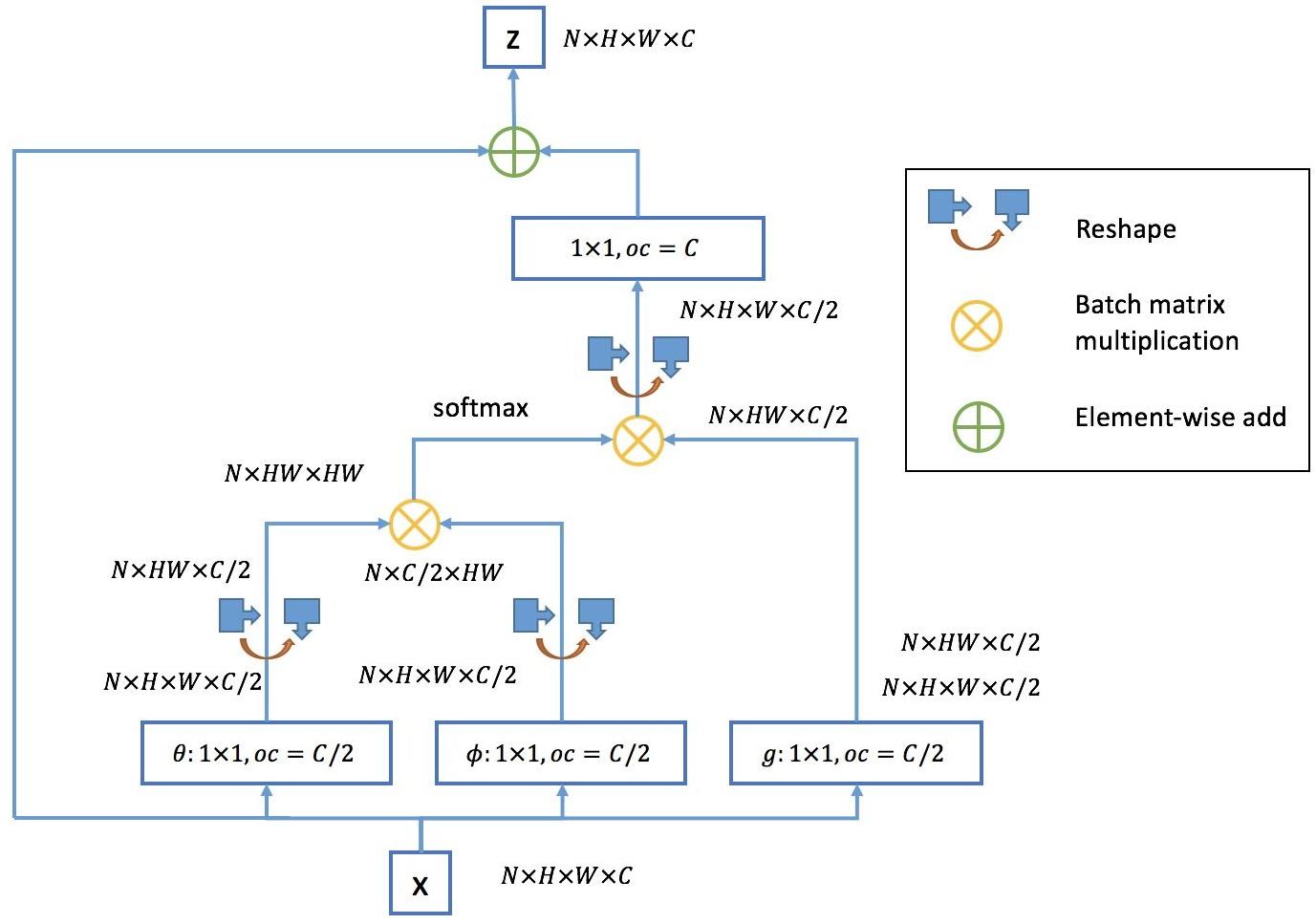
或者,如果一个样本内数据维度较高、数据之间存在较多的远距离依赖,那么可以考虑非局部神经网络(Non-local Neural Network),如下图所示。

Copyright © 2012-2018 开丰娱乐-开丰注册登录绿色站 版权所有 琼ICP备xxxxxxxx号
电话:0898-08980898 手机:13876453617 地址:海南省海口市




 在线咨询
在线咨询