0898-08980898 13876453617

0898-08980898 13876453617
爬虫小白继续负重前行,应朋友需要,爬取携程网上部分景点的游客评论数据,然后绘制评论数据的词云图,进而发掘用户的旅游期间的关注点。
最终效果如下:


1、爬取数据部分
使用火狐浏览器,打开携程网首页,登录个人账号(为了方便查看评论数据)。
在首页搜索框中输入景点名称,如:丽江古城,点击查询。

返回结果如下,并点击景点名称下面的评论数据:
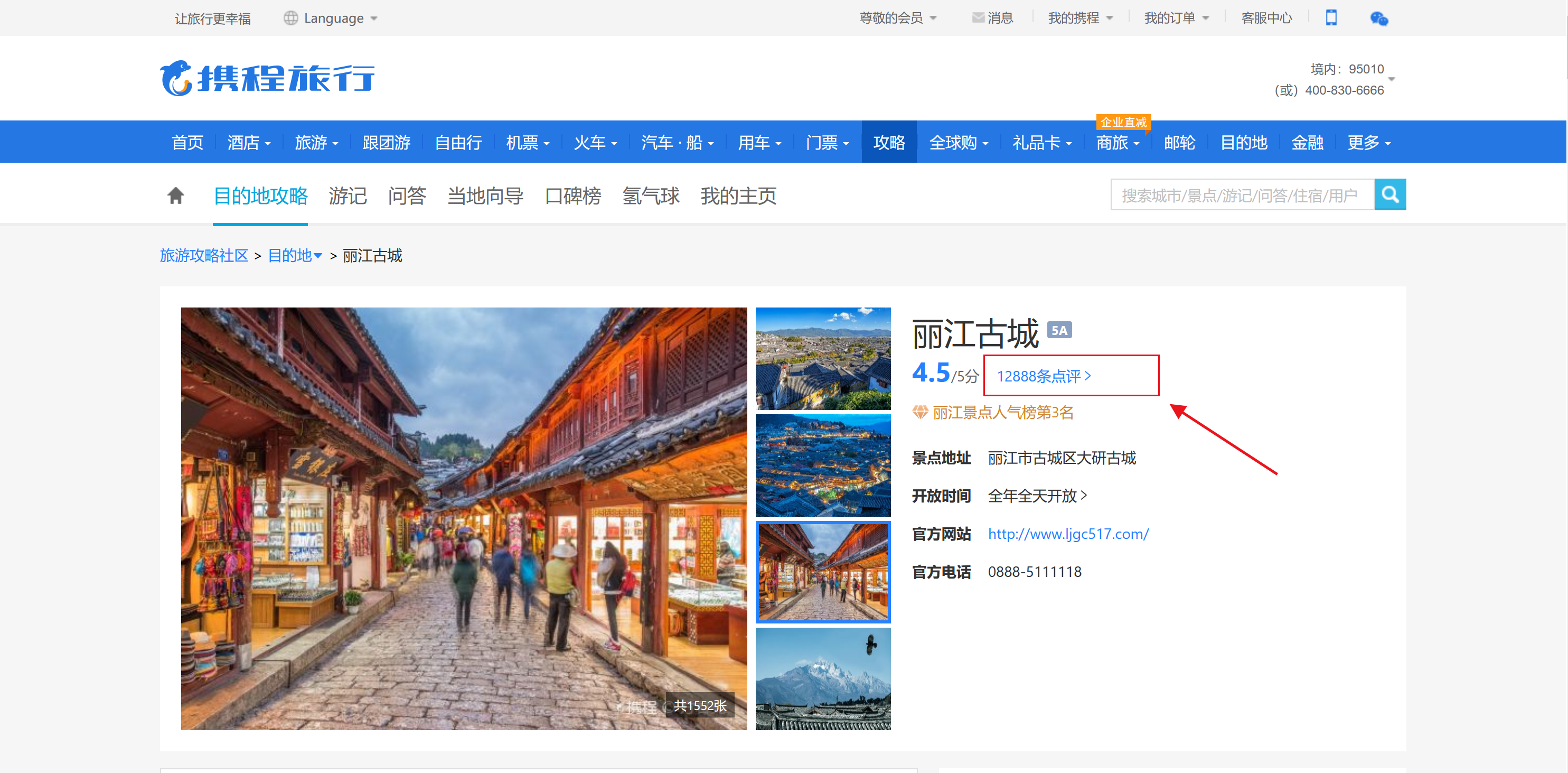
会自动跳转到该景点的评论内容,如下:
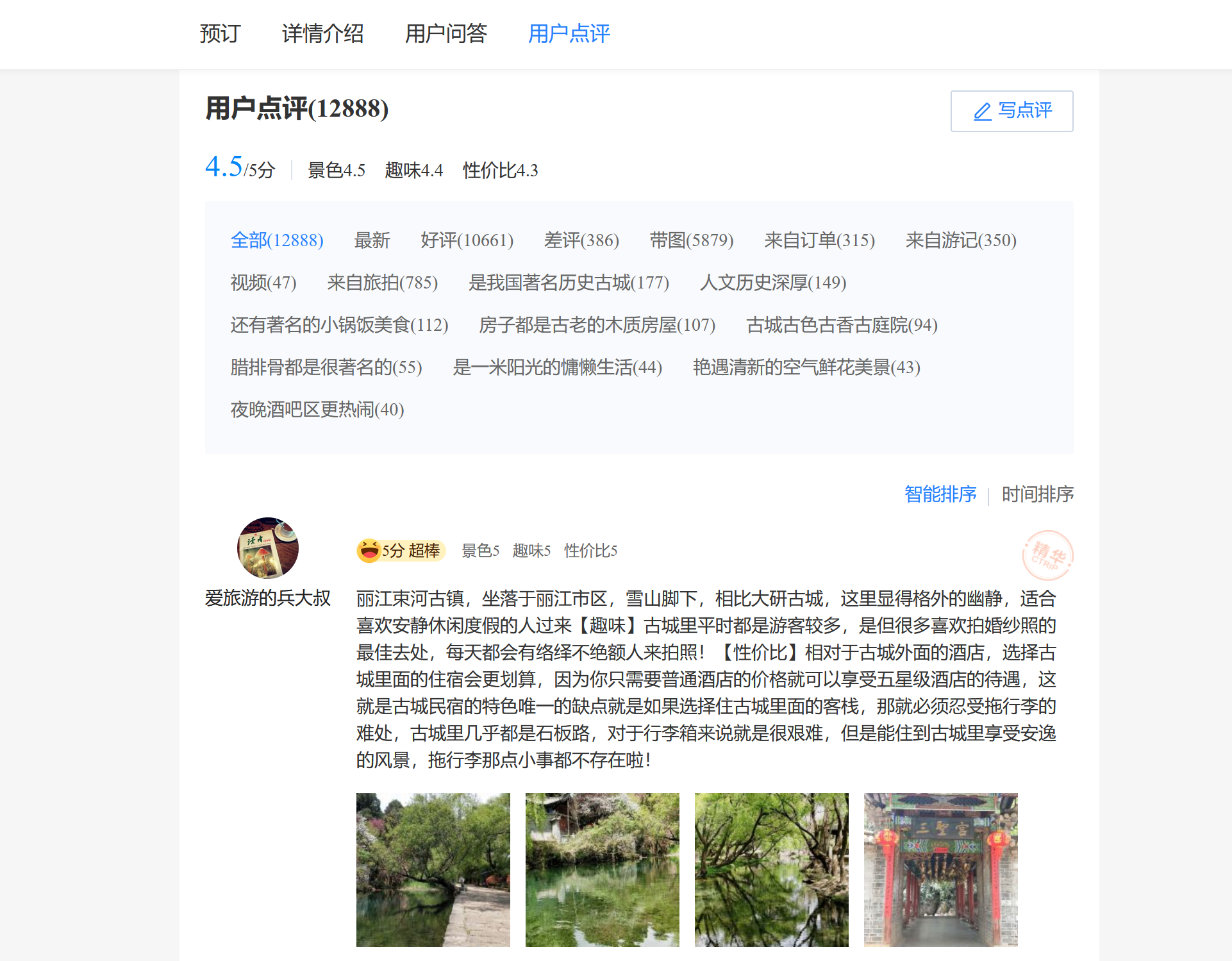
然后按快捷键F12,查看网页元素,如果没有反映,刷新网页即可。界面如下:
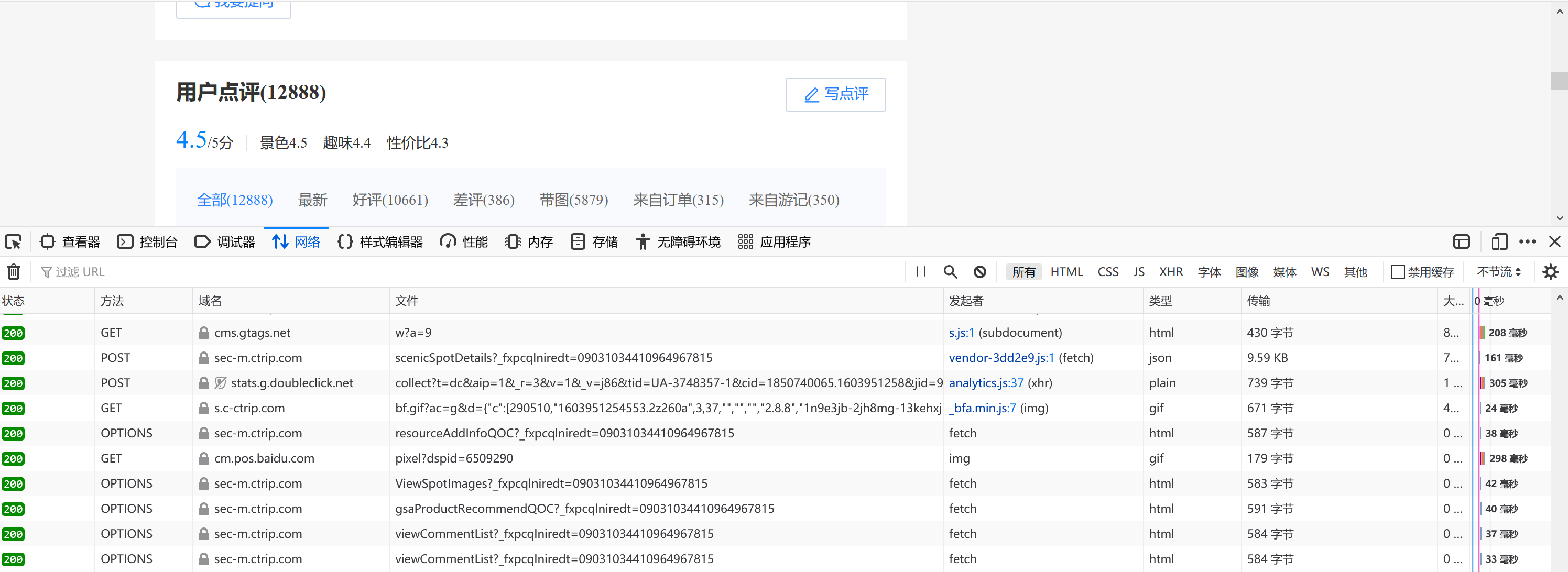
找到并点击上面页面中的“网络”,一般来说,按F12后会自动定位到“网络”这个选项。
然后在“过滤URL”框中输入“comment”,实现对URL的筛选,由于我们需要的是用户的评论数据,所以输入的关键词是comment。效果如下:

找到“方法”列值为“POST”的那两个URL,点击其中任意一个,会弹出右侧对话框,效果如下:
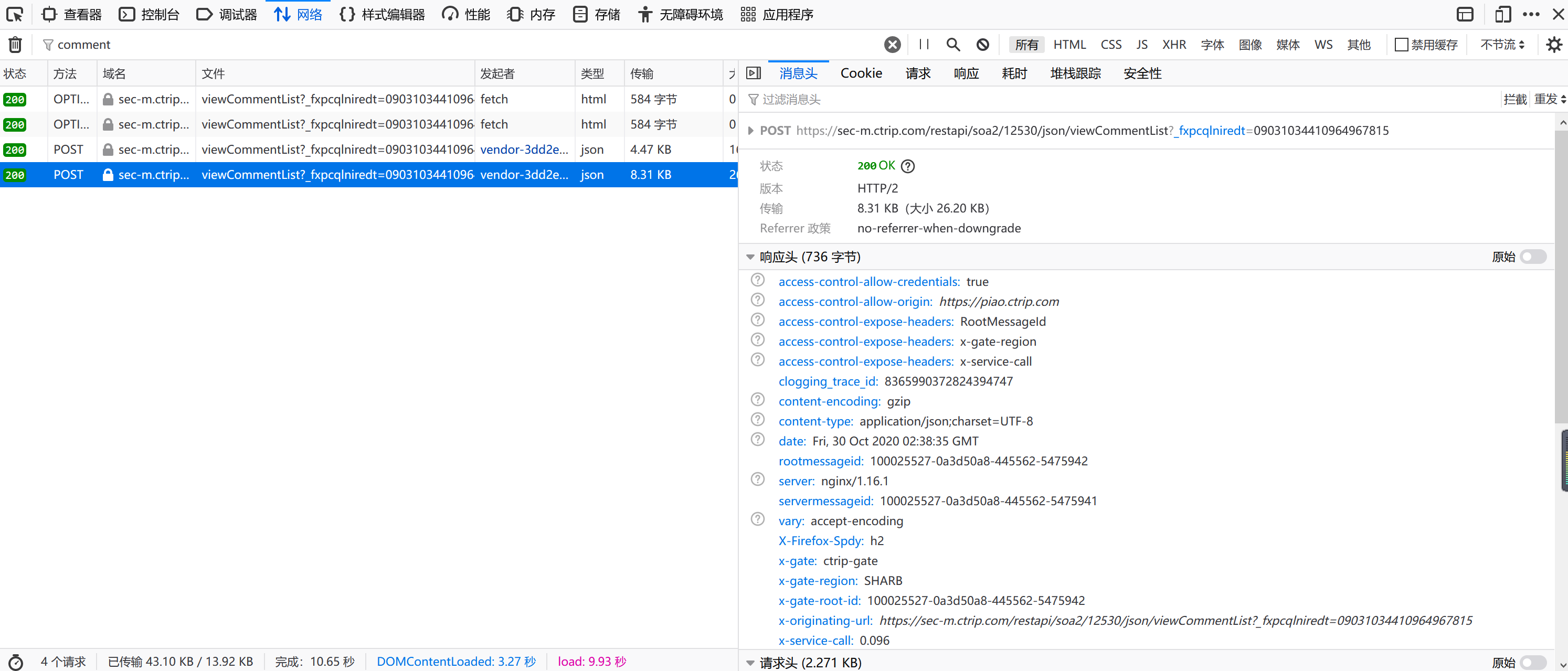
然后,找到并点击“请求”按钮,神奇的一击!我们需要的爬虫参数全都出来了~效果如下:
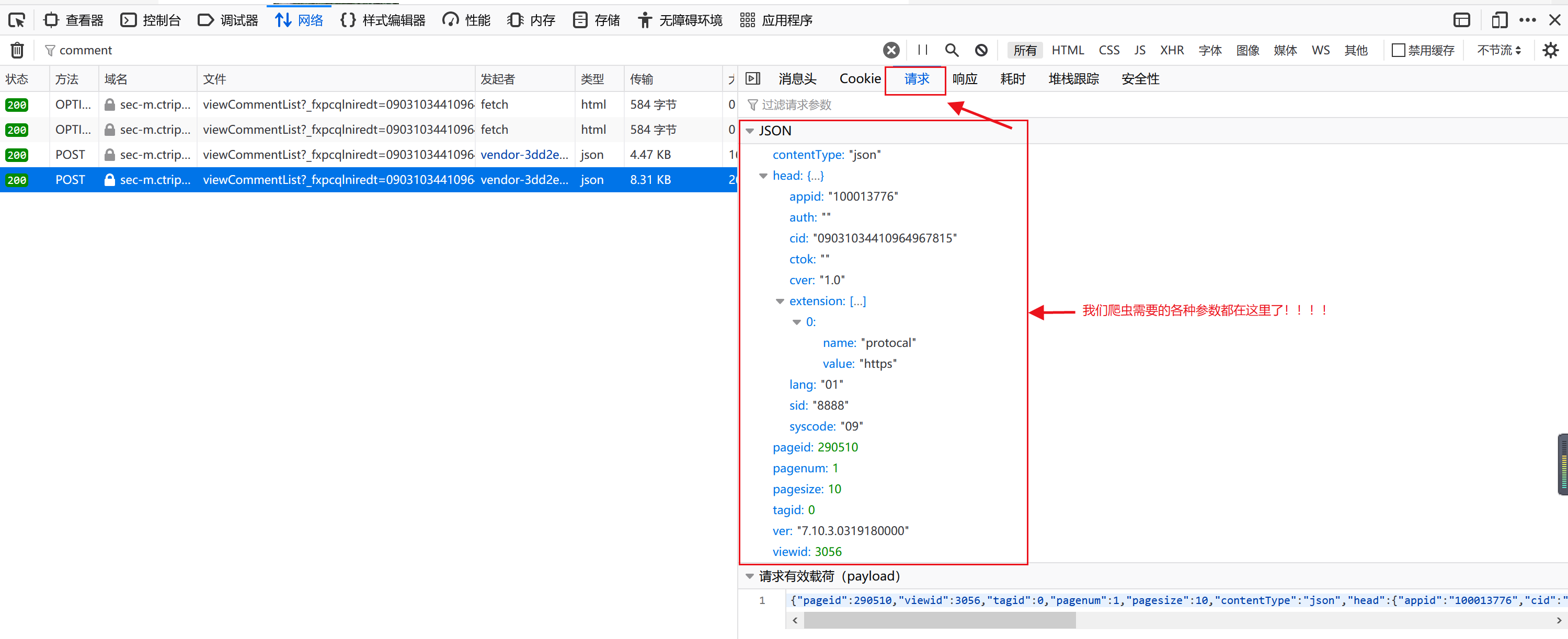
接下来的事情就相当无脑操作了,请大家复制下面的爬数据代码,并粘贴到你们的python运行环境中,然后,在代码中找到上面红色框中的参数的位置,并修改相应的参数值为待爬网页的参数即可。
如果你够细心,你就会发现上面截图最右下角有个“请求有效载荷”栏,里面的参数信息就是红色框中信息的压缩显示,而且可以直接复制“请求有效载荷”栏的信息替换爬虫代码中相应部分。
爬数据代码:
以下代码全部来自:松鼠爱吃饼干:Python爬虫案例:爬取携程评论
个人仅做了一些必要的备注。
import requests
import json
import time
import csv
import re
#爬取丽江评论
c=open(r'D:\\lijiang.csv','a+',newline='',encoding='utf8')#需要修改文件名为待爬景点的名字
fieldnames=['user','time','score','content']#设置存储最终爬虫结果的表格的字段名
writer=csv.DictWriter(c,fieldnames=fieldnames)
writer.writeheader()
#head 设置使用哪个浏览器进行爬虫
head={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'}
#评论内容所在连接,获取方法见代码注释①
postUrl="https://sec-m.ctrip.com/restapi/soa2/12530/json/viewCommentList"
#以下参数根据待爬网页相应的参数修改,或者直接复制“请求有效载荷”栏的信息进行替换
data_1={"pageid": "290510","viewid": "3056","tagid": "-11","pagenum": "1","pagesize": "10","contentType": "json","SortType": "1","head":{"appid": "100013776","cid": "09031096210696081838","ctok": "","cver": "1.0","lang": "01","sid": "8888","syscode": "09", "auth": "","extension":[{"name": "protocal","value": "https"}]},"ver": "7.10.3.0319180000"}
#"pagesize": "10"表示一页有10条评论
datas=[]#用来存放构建的60个请求头
for j in range(60):
#以下参数根据待爬网页相应的参数修改,或者直接复制“请求有效载荷”栏的信息进行替换,但是!注意,"pagenum": str(j + 1)表示翻页,不能替换掉!
data1={"pageid": "290510","viewid": "3056","tagid": "-11","pagenum": str(j + 1),"pagesize": "10","contentType": "json","SortType": "1","head":{"appid": "100013776","cid": "09031096210696081838","ctok": "","cver": "1.0","lang": "01", "sid": "8888","syscode": "09","auth": "","extension":[{"name": "protocal","value": "https"}]},"ver": "7.10.3.0319180000"}
datas.append(data1)
for k in datas[:60]:#循环抓取60页评论
print('正在抓取第' + k['pagenum']+ "页")
time.sleep(3)#延迟操作3秒,目的是模仿人类,防止被反爬机制识别出来是爬虫机器人
#因为用户评论使用的是post方法,所以下面我们也要使用post方法请求网页,text方法用于提取网页中文本内容
html1=requests.post(postUrl, data=json.dumps(k)).text
#json.loads()将返回的网页信息从json格式转为dict(字典)格式,方便后续进行信息提取
html1=json.loads(html1)
#提取网页文本中的评论内容,为什么要这么写?这需要我们对一个具体网页信息进行分析,分析过程见注释②
comments=html1['data']['comments']
#注意,comments是一个列表,列表中每个元素是一个存放了用户各种信息的字典,包括用户ID、用户评论日期、评论内容、评分……
#所以,comments的格式:[{"id":123,"content":"不错的一次体验","score":'4'},{第2个用户的评论相关信息},{第3个用户的评论相关信息},....]
for i in comments:#循环提取comments列表中每个用户的ID、评论日期、打分、评论内容
user=i['uid']
time1=i['date']
score=i['score']
content=i['content']
content=re.sub(" ", "", content)#使用正则表达式对提取到的评论内容进行处理
content=re.sub("", "", content)
writer.writerow({'user': user,'time':time1,'score': score,'content':content})#把单个用户的评论信息写入表中
c.close()
#由于csv文件直接打开会乱码,下面读入爬取好的数据,转换为xlsx格式并保存
import pandas as pd
pd=pd.read_csv('D:\\lijiang.csv',encoding='utf8')
pd.to_excel('D:\\lijiang.xlsx',encoding='utf8')注释:
①postUrl获取办法:点击“消息头”---找到“POST”,后面红色框内的链接就是评论内容的链接。
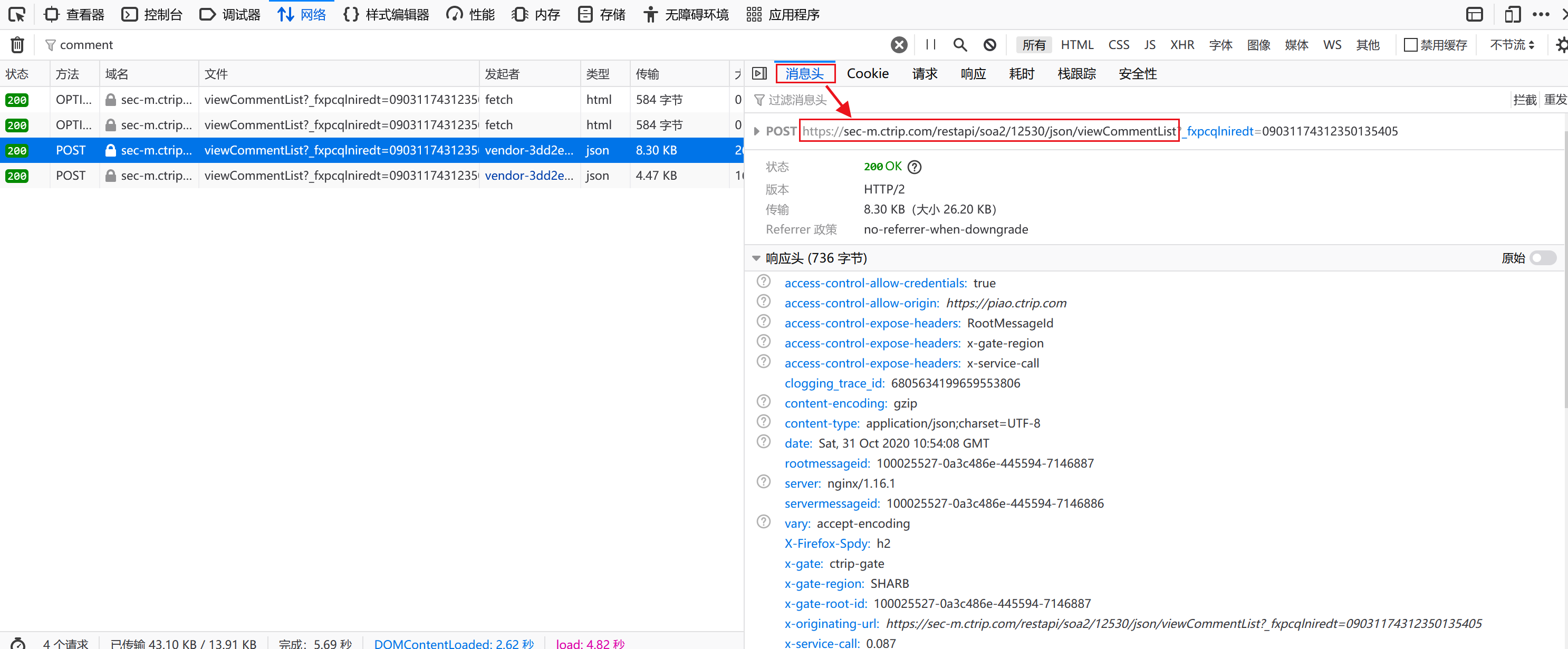
②单个网页解析
抓取后的一个网页的html样子如下,因为单个网页有10条用户评论,在不改变原来数据结构的前提下,为了方便演示,这里只展示了2个用户评论。
原始网页并没有下面这么“优美”的结构,层次分明,我们需要先下载单个网页来分析网页结构,进而才能准确定位我们需要的信息。分享网页分析的两个技巧:
1)将爬取的单个网页粘贴到python编译器中,如Pycharm,使用光标来发现层次关系。如将光标点击到“[”,Pycharm会自动高亮同一层次对应的"]"所在的位置。
2)根据目标导向,我们需要的核心数据是用户的评论,由于都是中国人,评论数据自然是中文,用肉眼定位大片中文,然后结合光标来发现网页内容的层次关系。
通过下面的网页,我们可以发现,我们需要的数据具体位置:
{......
"data":{
.......
"comments":[{
"id":164903024,
"content":'丽江古城是位于我国西南边陲,是我国茶马古道上重要一站,是云南到西藏的必经之道,大量的马帮 和商队造就了这个城市的兴起和繁华。',
"score":"5",
.......
}]},}
{'ResponseStatus':{'Timestamp': '/Date(1604143571534+0800)/', 'Ack': 'Success', 'Errors':[], 'Build': None, 'Version': None, 'Extension':[{'Id': 'CLOGGING_TRACE_ID', 'Version': None, 'ContentType': None, 'Value': '2859573375097530598'},{'Id': 'RootMessageId', 'Version': None, 'ContentType': None, 'Value': '100025527-0a19b172-445595-4086166'}]},
'head':{'auth': '', 'errcode': 0, 'errmsg': ''},
'data':{'cmtquantity': 12890,
'cmtscore': 4.5,
'totalpage': 1289,
'recompct': '97%推荐',
'stscs':[{'tagid': -21, 'count': 5880, 'desc': '带图', 'moodtype': 0, 'location': 'tab'},{'tagid': -12, 'count': 386, 'desc': '低分', 'moodtype': 0, 'location': 'tab'},{'tagid': -250, 'count': 12890, 'desc': '最近游玩', 'moodtype': 0, 'location': 'tab'},{'tagid': -22, 'count': 315, 'desc': '来自订单', 'moodtype': 0, 'location': 'tag'},{'tagid': -24, 'count': 47, 'desc': '视频', 'moodtype': 0, 'location': 'tag'},{'tagid': -25, 'count': 786, 'desc': '来自旅拍', 'moodtype': 0, 'location': 'tag'}],
'comments':[{'id': 164903024,
'uid': '周游列国',
'userImage': 'https://dimg04.c-ctrip.com/images/Z8070a0000004m9t7BB14_C_180_180.jpg',
'title': '',
'content': '丽江古城是位于我国西南边陲,是我国茶马古道上重要一站,是云南到西藏的必经之道,大量的马帮 和商队造就了这个城市的兴起和繁华。',
'date': '2020-10-29 07:56',
'score': '5',
'isselect': False,
'simgs':['https://dimg01.c-ctrip.com/images/0103o1200087imt2yA5F1_C_160_160_Q60.jpg', 'https://dimg06.c-ctrip.com/images/0104b1200087iikinFAA3_C_160_160_Q60.jpg', 'https://dimg05.c-ctrip.com/images/010021200087iio2h63C4_C_160_160_Q60.jpg', 'https://dimg08.c-ctrip.com/images/0106g1200087iles769CD_C_160_160_Q60.jpg', 'https://dimg03.c-ctrip.com/images/010561200087imnl15679_C_160_160_Q60.jpg', 'https://dimg04.c-ctrip.com/images/010461200087iijjc499B_C_160_160_Q60.jpg'],
'bimgs':['https://dimg01.c-ctrip.com/images/0103o1200087imt2yA5F1_C_640_360_Q60.jpg', 'https://dimg06.c-ctrip.com/images/0104b1200087iikinFAA3_C_640_640_Q60.jpg', 'https://dimg05.c-ctrip.com/images/010021200087iio2h63C4_C_640_480_Q60.jpg', 'https://dimg08.c-ctrip.com/images/0106g1200087iles769CD_C_480_640_Q60.jpg', 'https://dimg03.c-ctrip.com/images/010561200087imnl15679_C_360_640_Q60.jpg', 'https://dimg04.c-ctrip.com/images/010461200087iijjc499B_C_480_640_Q60.jpg'],
'videos':[],
'replyeditor': None,
'reply': None,
'usecount': 3,
'sourcetype': 0,
'playdate': '',
'keywordlist': None,
'cmttype': 'others',
'commentOrderInfo': '',
'commenter': True,
'memberLevel': 10,
'memberName': '黄金贵宾',
'sightStar': 5,
'interestStar': 5,
'costPerformanceStar': 5},
{'id': 164919071,
'uid': 'ALAN628',
'userImage': 'https://dimg04.c-ctrip.com/images/t1/headphoto/136/299/437/649eb217e3e54746b7a53b8665e14b00_C_180_180.jpg',
'title': '',
'content': '值得!
到丽江的第一天就去了那里,看你游玩时间,如果紧张的话,5个小时肯定也够了而且建议在里面吃饭,你要买的鲜花饼牛肉干冰粉烧烤米线都可以买到吃到',
'date': '2020-10-28 17:58',
'score': '5',
'isselect': False,
'simgs':['https://dimg01.c-ctrip.com/images/010201200087hq1vq2D0B_C_160_160_Q60.jpg', 'https://dimg07.c-ctrip.com/images/0106q1200087hpy56633F_C_160_160_Q60.jpg', 'https://dimg07.c-ctrip.com/images/0102a1200087howr7D44B_C_160_160_Q60.jpg', 'https://dimg08.c-ctrip.com/images/010321200087hppkoFDB1_C_160_160_Q60.jpg', 'https://dimg06.c-ctrip.com/images/0102b1200087hnz0tAEE5_C_160_160_Q60.jpg'],
'bimgs':['https://dimg01.c-ctrip.com/images/010201200087hq1vq2D0B_C_480_640_Q60.jpg', 'https://dimg07.c-ctrip.com/images/0106q1200087hpy56633F_C_480_640_Q60.jpg', 'https://dimg07.c-ctrip.com/images/0102a1200087howr7D44B_C_480_640_Q60.jpg', 'https://dimg08.c-ctrip.com/images/010321200087hppkoFDB1_C_480_640_Q60.jpg', 'https://dimg06.c-ctrip.com/images/0102b1200087hnz0tAEE5_C_360_640_Q60.jpg'],
'videos':[],
'replyeditor': None,
'reply': None,
'usecount': 0,
'sourcetype': 0,
'playdate': '',
'keywordlist': None,
'cmttype': 'others',
'commentOrderInfo': '',
'commenter': False,
'memberLevel': 30,
'memberName': '钻石贵宾',
'sightStar': 5,
'interestStar': 5,
'costPerformanceStar': 5}],
'abtests':[]}}使用同样的方法爬取其他几个景点的评论数据:世界之窗、嵩山、锦绣中华民俗村。
2.绘制词云代码
涉及的额外语料主要是停用词表:
链接:https://pan.baidu.com/s/1dOpMKYCC-b9wkLv8WAySuA
提取码:w2ah
以下代码为本人原始手打,未精加工,可实现功能而已。
#读入数据
import pandas as pd
path1='D:\\\\lijiang.csv'
rawdata1=pd.read_csv(path1,header=0,encoding='utf8')
print(rawdata1['content'].head(5))#查看前5条评论数据
print(rawdata1['content'].shape)#查看评论数据条数
comments1=rawdata1['content']
path2='D:\\\\shijiezhichuang.csv'
rawdata2=pd.read_csv(path2,header=0,encoding='utf8')
print(rawdata2['content'].head(5))#查看前5条评论数据
comments2=rawdata2['content']
path3='D:\\\\songshan.csv'
rawdata3=pd.read_csv(path3,header=0,encoding='utf8')
print(rawdata3['content'].head(5))#查看前5条评论数据
comments3=rawdata3['content']
path4='D:\\\\jinxiuzhonghua.csv'
rawdata4=pd.read_csv(path4,header=0,encoding='utf8')
print(rawdata4['content'].head(5))#查看前5条评论数据
comments4=rawdata4['content']
#拼接评论数据
import numpy as np
allcomments=np.concatenate([comments1,comments2,comments3,comments4],axis=0)
print(allcomments.shape)
print(allcomments)
allcomments_pd=pd.DataFrame({'comments':allcomments})
print(allcomments_pd.tail(5))#查看后5行数据
#不进行分词也可以直接提取关键词,并基于关键词绘制词云
import jieba.analyse
lst=[]
for i in allcomments_pd['comments']:
lst.append(i)
s=','.join(lst)#jieba抽取关键词需要输入字符串
keywords=jieba.analyse.extract_tags(s,topK=100,withWeight=True,allowPOS=('n'))#topK=100表示提取前100个关键词,allowPOS=('n')表示只提取名词
print(keywords)#[('景色', 0.38318375268326504), ('体验', 0.20224094490946254), ..., ('价格', 0.013745652994182062)],数字为关键词的权重
#仅抽取出关键词,不要权重
wordslst=[]
for i in range(len(keywords)):
w=keywords[i][0]
wordslst.append(w)
print(wordslst)
#去除关键词中的停用词
stopwords_path='D:\\\\宝宝Zone\\\\爬取携程旅游景点评论数据并绘制词云\\\\stopwords.txt'
with open(stopwords_path, mode='r', encoding='utf-8') as f:
lines=f.readlines()
stopwords=[line.strip() for line in lines]
#print(stopwords)
# 去停用词
words_without_stopwords=[w for w in wordslst if w not in stopwords]
print(len(words_without_stopwords))#去除停用词后只有75个词了
#绘制词云
import wordcloud
words_string=','.join(words_without_stopwords)#词云图输入的数据类型要求为字符串,因此,需要将列表中的元素使用逗号拼接成字符串
wc=wordcloud.WordCloud(max_words=60,font_path='msyh.ttc',width=800,height=600)
#max_words=60表示词云图中最多放60个词,font_path='msyh.ttc'表示词云图的字体用微软雅黑,width=800,height=600分别为词云图的宽度和高度
wc.generate(words_string)
wc.to_file('C:\\\\Users\\\\Cara\\\\Desktop\\\\mywordcloud.png')在绘制词云时的一点小经验,因为本次实验的目的是获取游客关注的点,并选取了嵩山、丽江古城、世界之窗、锦绣中华民俗村等景点作为代表,所以,可以想象,点评数据中一定会出现“嵩山、丽江古城、世界之窗、锦绣中华民俗村”等高频词,而这些高频词绘制在词云图中的意义不大,因此,我们可以将这些词放在停用词表中,在分词后,去停用词时去掉。
参考:
松鼠爱吃饼干:Python爬虫案例:爬取携程评论中文分词工具jieba中的词性类型 - Adien - 博客园
Copyright © 2012-2018 开丰娱乐-开丰注册登录绿色站 版权所有 琼ICP备xxxxxxxx号
电话:0898-08980898 手机:13876453617 地址:海南省海口市




 在线咨询
在线咨询