0898-08980898 13876453617

0898-08980898 13876453617
最近的一项工作应用机器学习技术来辅助或重建DBMS中基于成本的查询优化器。虽然在某些基准测试中表现出优越性,但它们的缺陷,例如性能不稳定、训练成本高、模型更新速度慢,源于使用机器学习模型预测执行计划的成本或延迟的固有困难。在本文中,我们介绍了一种称为 Lero 的 learning-to-rank 查询 optimizer,它建立在本地查询优化器之上,并不断学习提高优化性能。关键观察是计划的相对顺序或排名,而不是确切的成本或延迟,足以进行查询优化。Lero 采用成对方法训练分类器来比较任意两个计划并判断哪个更好。在模型效率和准确性方面,这种二元分类任务比回归任务更容易预测成本或延迟。Lero 不是从头开始构建学习的优化器,而是旨在利用数十年的数据库智慧并改进本地查询优化器。凭借其非侵入式设计,Lero 可以在任何现有的 DBMS 之上实现,只需最少的集成工作。我们实现了 Lero 并使用 PostgreSQL 展示了其出色的性能。在我们的实验中,Lero 在几个基准测试中实现了近乎最佳的性能。它将 PostgreSQL 中原生优化器的计划执行时间减少了多达 70%,其他学习查询优化器减少了高达 37%。同时,Lero 不断学习和自动适应查询工作负载和数据的变化。
查询优化器在数据库中扮演着最重要的角色之一。它旨在为每个查询选择一个有效的执行计划。提高其性能一直是一个长期存在的问题。传统的基于成本的查询优化器[40]以最小的估计成本找到计划,这是执行延迟或其他用户指定的资源消耗指标的代理。这种成本模型包含各种公式来近似实际执行延迟,其魔常数数根据工程实践详尽而广泛调整。最近的工作[32, 33, 51]使用机器学习技术改进了传统的成本模型和计划枚举算法。尽管已经取得了一些进展,但它们仍然存在由本质上困难的延迟预测问题引起的缺陷。在本文中,我们提出了 Lero,这是一种学习排序查询优化器,它具有用于查询优化的新的轻量级成对机器学习模型。Lero采用非侵入式设计,对DBMS中的现有系统组件进行最小的修改。Lero 不是从头开始构建的,而是旨在利用数十年的查询优化器智慧,而无需额外、可能显着、冷启动的学习成本。Lero可以通过明智地探索不同的优化机会和学习更准确地对它们进行排名来快速提高查询优化的质量。
传统的基于成本的查询优化器[40]有三个主要组成部分:基数估计器、成本模型和计划枚举器。对于输入查询Q,可以调用基数估计器来估计基数,即输出中的元组数量,对于Q的每个子查询。查询Q的计划P(带有物理运算符,例如merge join和hash join)的成本是延迟或其他用户指定指标的代理,以了解执行P效率。成本模型 PlanCost(P) 估计P的成本,通常是Q子查询的估计基数的函数。计划枚举器在其搜索空间中考虑 Q的有效计划,并返回具有最小估计执行成本的计划。
各种启发式方法对于开发这些组件至关重要。例如,假设跨表的属性之间的独立性,并用于估计多个表的连接的基数[24,45]。Magic常数数字在成本模型中很普遍。它们通常多年来进行校准和调整,以确保在某些系统和硬件配置下,估计的成本在经验上与计划的性能相匹配。意识到这种启发式方法对于不同的数据分布或系统配置并不总是可靠的。因此,成本模型可能会产生重大错误,传统查询优化器生成的计划质量可能较差。
开发机器学习模型来替换传统的基数估计器、基于启发式的成本模型和计划枚举器是很自然的想法。例如,有关于学习基数估计器的工作(有关调查,请参阅[16, 59])。对于学习成本模型,可以从不同的数据集和工作负载中学习不同的模型参数,而不是传统成本模型中的固定魔常数数,以实现对各种数据分布和系统配置的细粒度表征,从而为每个查询提供实例级优化。最近关于学习查询优化器的工作建立在上述思想之上,并展示了一些有希望的结果。
Neo[33]和Balsa[51]为查询优化提供了端到端学习的解决方案。学习受深度强化学习价值网络启发的计划价值函数 PlanVal() 来替换传统的成本模型 PlanCost。对于查询Q的部分计划P‘,机器学习模型PlanVal(P‘,Q)预测包含P‘作为子计划的完整计划P的最小延迟,将关于P’和Q中涉及的表格、谓词和连接的统计和模式作为输入特征。使用 PlanVal,Neo 和 Balsa 使用他们最好的优先搜索策略来找到具有最小估计延迟的最佳计划。
Bao[32]学习引导本地查询优化器。它使用不同的提示集调整本机查询优化器,为查询生成许多不同的候选计划 .每个提示集强制/禁用一些操作,例如索引扫描或散列联接,因此查询优化器可以输出不同的、可能更好的执行计划。Bao使用机器学习模型PlanVal( , )估计每个候选计划P的质量(例如,延迟)并选择用于执行的最佳候选者。同时,Bao 使用 Thompson 采样[43]根据执行统计定期更新其模型参数,作为解决上下文多臂老虎机问题[56]以最小化整体性能遗憾。
尽管学习到的查询优化器在某些应用[37]中表现出优于传统查询优化器的优越性,但它们的性能远远不能令人满意。它们仍然存在三个主要缺陷:
? (1)不稳定的性能。这些学习的模型很容易产生不准确的延迟估计,从而导致次优计划。有时,性能回归非常显着。如第 6.2 节所述,它们的性能甚至可以比 PostgreSQL 在 TPC-H 基准上的本地查询优化器差。
? (2)高学习成本。学习查询优化器的成本包括探索和执行不同查询计划的成本和模型训练的成本。一些模型[33,51]需要数十到数百个训练迭代来覆盖,并在每次迭代中执行所有新探索的计划。对于复杂的数据集,这将消耗几天甚至几周。
? (3)缓慢的模型更新。现有的学习优化器需要更新它们的延迟预测模型以适应动态数据,这是非常具有挑战性的,特别是考虑到同一计划的延迟可能在动态数据上有所不同。因此,在这种情况下,模型更新需要大量的努力(训练数据和成本),并且很容易导致性能回归,如第 6.4 节所述。
我们认识到,传统和新提出的学习查询优化器的缺陷源于预测计划执行延迟或成本的众所周知的难题。确切的执行延迟取决于许多因素[24,25,34,39,49],例如底层数据分布、工作负载模式和系统环境。训练这样的预测模型是一项昂贵的操作,它需要通过执行查询计划和测量延迟统计数据来收集大量训练数据,以及一个冗长的训练过程来探索巨大的假设空间。此外,基数和成本估计只是查询优化的部分因素。无论使用传统的校准估计器/模型还是使用在以前的统计数据上训练的学习模型,提高估计的准确性并不一定会导致查询优化的改进。
是否真的有必要预测延迟。我们问这样一个基础研究问题:为了查询优化的目的,我们真的需要估计/预测每个可能的查询计划的执行延迟(或任何其他与性能相关的度量)。为了找到最佳执行计划,训练一个机器学习模型来预测确切的延迟(成本)是一个过度杀伤。
传统的成本模型本质上是“人类学习”模型,其参数(即魔法常数数)已经经过几十年的工程努力进行了调整。在learn-to-rank范式下,传统和学习的成本模型可以看作是pointwise approach[28],它为每个计划输出一个序数分数(即估计成本)来对它们进行排名。Lero 采用了一种有效的pairwise approach排序方法,而不会丢弃人类智慧来开发传统的成本模型和查询优化器。
learn-to-rank范式:一种机器学习范式,用于解决排序问题。在Learn-to-Rank中,模型被设计用于学习如何将一组项目或实例进行排序,以便根据某个特定的目标或标准对它们进行排序。
pointwise方法:在逐点方法中,每个样本或文档被视为一个单独的实例,独立于其他实例。这意味着模型的训练和预测是针对每个数据点进行的,而不是考虑整体数据集的交互关系。
pairwise方法:该方法关注两个数据点之间的比较,学习如何对给定的一对数据点进行排序或分类。在排名任务中,可以学习哪个文档在给定查询下更相关。
我们总结了我们的贡献如下:
? (1)Lero将learn-to-rank范式应用于查询优化。与之前提出的学习成本模型或基数(查询优化的部分因素)相比,Lero直接排序和学习可以提高计划的质量。Lero在选择质量好的计划方面更有效。
? (2)Lero 采用pairwise方法来学习比较两个计划并预测更好的计划。与其他pointwise方法相比,训练这样的二元分类器通常更容易[19]。Lero 的训练成本显着降低,需要更少的训练样本,训练时间要少得多。pairwise比较模型也用于[10]中的索引调优。Lero 实现了一种新颖的深度学习模型,该模型由具有共享参数的两个计划嵌入上的分类器组成。该模型能够捕获给定计划的详细结构属性,并在查询优化的背景下被证明更有效。
? (3)Lero 能够更有效地探索和学习新的计划空间(以及新的优化机会)。Lero 不像以前的方法[32]那样使用查询级提示,而是可以配备各种策略来调整表达水平的基数估计,以有效地考虑多样化的计划并优先考虑探索更有前途的计划。
? (4)Lero利用了数十年的数据库和查询优化智慧,而不是从头开始构建全新的优化器。Lero 从本地查询优化器的默认行为开始,并逐渐学会改进。因此,Lero 保证具有良好的初始质量,不需要冗长的冷启动训练过程。
? (5)Lero 采用非侵入式设计。它可以在任何现有的 DBMS 之上实现,并与本地查询优化器无缝集成。具体来说,Lero 利用大多数 DBMS 提供的公共接口,并与本地查询优化器联合工作以提高优化质量
Lero是一个learning-to-rank query optimizer,它不断探索不同的查询计划,观察它们的性能,并学习更准确地对它们进行排序。Lero采用pairwise方法,其目的是预测两种计划中哪一种更有效。
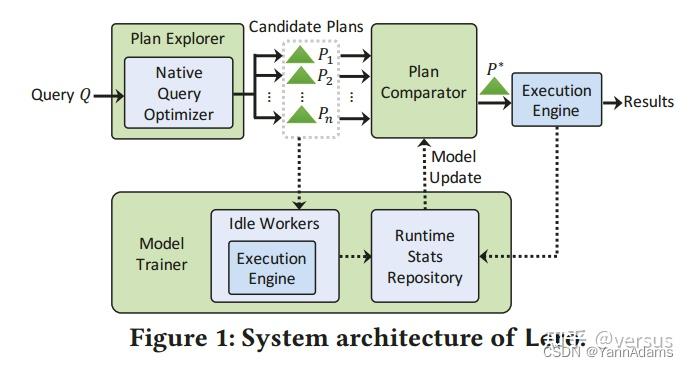
图1显示了Lero的整体架构。对于每个输入查询Q,plan explorer与本机query optimizer一起生成许多可能良好且多样化的候选计划$P_{1}$, $P_{2}$, ..., $P_{n}$。然后调用pairwise plan comparator model CmpPlan从回答Q的候选计划中选择最佳计划。在系统后台,model trainer在系统资源可用时使用空闲workers执行其他候选计划,将延迟信息收集到运行时状态存储库中,并持续训练comparator model CmpPlan并定期更新它。这种设计使comparator model能够不断地训练,并随着时间的推移变得更好,而不会影响正常的数据库服务。下面简要介绍这三个组成部分:

为了满足这两个需求(two requirements),我们的plan explorer使用基数估计器作为调优旋钮,为每个查询生成更多的计划:在将子查询的基数估计输入到本机查询优化器的成本模型中以生成不同的候选计划之前,会有意地scaled up/down。特别的,它表明可以通过调整查询中谓词的选择性(基数)在生成的计划中引入多样性。我们的计划探索者建立在这样一种直觉之上,即来自本地查询优化器的计划通常不太糟糕;通过调整基数估计,它可以在相邻计划空间中生成一些更好的计划(如果针对错误估计的子查询的真实成本进行调整),或者一些更差的计划(以相反的方向调整)。质量各异的计划也增加了候选计划的多样性,以训练comparator,而comparator的作用是在候选计划中找出最优的计划。
关于我们的plan explorer策略的详细信息在第 4 节中描述。我们的plan explorer的一个明显优势是基数估计器在几乎所有查询优化器中都是必不可少的组件,因此我们的计划探索器的策略和实现可以很容易地迁移到不同的数据库中。
比较器CmpPlan被训练/更新以适应来自运行时统计存储库的训练数据集,该存储库持续监控查询执行并收集执行信息。
comparator CmpPlan()的整体模型架构如图2所示。它由plan embedding layers和comparison layer组成。
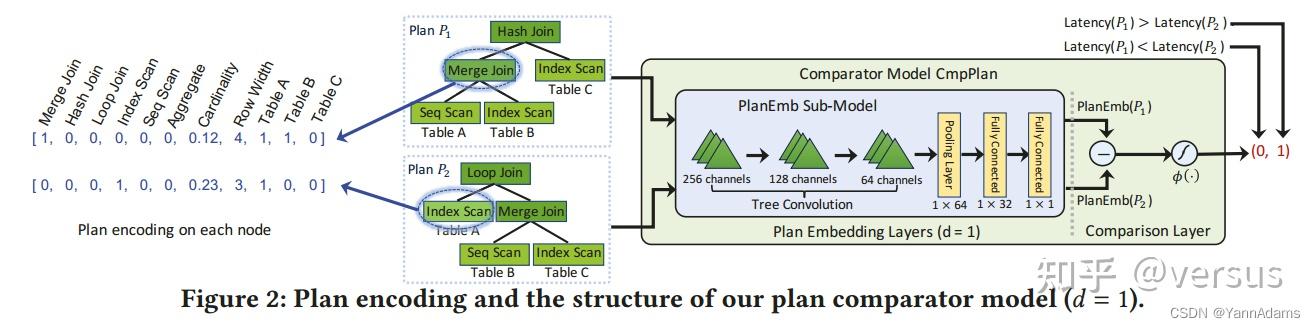
plan embedding layers可以有效地捕获查询计划的所有关键信息,包括表、操作符和计划结构属性等,comparison layer比较两个计划的embeddings(embedding layers输出的1-dim或d-dim向量),并计算它们在计划质量方面的差异,以进行比较。
学到的1- 计划嵌入可以被解释为一个排名标准,并且基于PlanEmb(·),查询的所有计划对都是可比较的。因此,PlanEmb的规模( )对于一个计划 不受限制,其值不必与(或近似)成比例 's的性能指标,例如延迟。这种灵活性使整个模型更有效,更容易训练。


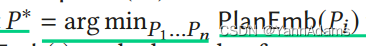


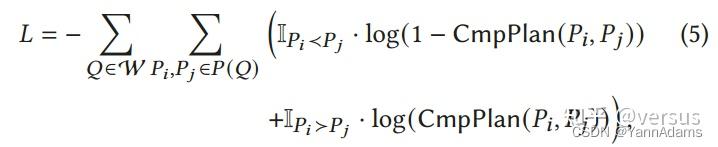
模型不是从头开始训练,而是首先在合成工作负载上离线预训练comparator model CmpPlan,以继承本机query optimizer及其cost model的智慧。然后,使用在实际执行查询计划期间收集的训练数据,在真实工作负载上对其进行持续的在线训练和更新。
Model Pre-training: Starting from Traditional Wisdom
在离线训练阶段,我们使用候选计划的估计成本(不执行它们)对comparator model进行训练,候选计划是在特定训练阶段从查询的样例工作负载中生成的。预训练后,1-dim embedding PlanEmb(P)被期望是原生估计成本PlanCost(P)的近似值。因此,该模型在开始时被引导以执行与本机查询优化器类似的操作。随着越来越多的查询被执行,CmpPlan不断得到改进和调优,以适应可能的动态数据分布和随时间漂移的工作负载。
预训练PlanEmb(P)的目标是以一种与数据无关的方式学习这些函数,以便处理任何看不见的查询。因此,我们可以完全地使用合成工作负载预训练PlanEmb(P)。即,我们在不同的表上随机生成一些具有不同连接顺序和谓词的计划,并将其作为训练数据;我们还随机设置每个计划的每个子计划的基数,并将它们输入到本地cost model中(不执行计划),以获得估计的计划成本作为标签。由于cost models通常属于一类结构简单的函数,因此模型预训练收敛速度很快。
Pairwise Training
在在线阶段,我们在pairwise comparison框架中训练和更新comparator CmpPlan。对每个查询Q,它的候选计划{$P_{1}$, ..., $P_{n}$}由plan explorer生成,在系统资源可用时,这些计划由空闲workers执行,执行信息收集在runtime stats repository中。根据公式5的损失函数,我们为每个查询构建n(n-1)个训练数据点,对每个pair(i,j)构建数据点features($P_{i}$, $P_{j}$)和标签0/1(如果Latency($P_{i}$) > Latency($P_{j}$)标记为1,否则标记为0)。
我们使用SGD optimizer周期性地使用上面构造的训练数据集通过反向传播来更新CmpPlan和PlanEmb。对于子模型PlanEmb中的参数,因为它们在PlanEmb的两个副本中共享,分别输出PlanEmb($P_{i}$)和PlanEmb($P_{j}$),我们将共享参数的两个副本的梯度加在一起,以更新模型PlanEmb中的参数。
Lero的plan explorer为查询Q生成候选计划列表 $P_{1}$,…,$P_{n}$ ,有两个目的。
Existing Plan Exploration Methods
Lero使用cardinality estimator作为plan explorer的调优旋钮。在Lero的plan explorer中,我们多次调优(放大或缩小)估计的基数,以生成不同候选计划的列表。C()是本机的cardinality estimator,对于查询Q的子查询Q',C(Q')给出了基数估计。有别于在cost model中调用C(),我们要求query optimizer调用一个tuned estimator ($\\widetilde{C}$),因此它将生成一个不同的计划。我们的plan explorer将以不同的方式调优C();通过将不同的tuned estimators输入到cost model中,query optimizer将生成不同的计划作为候选列表$P_{1}$,…,$P_{n}$。使用cardinality estimator作为调优旋钮有以下优点:
A Brute-Force Exploration Strategy 暴力探索策略
定义 $C^{}(Q)$是实际基数,C(Q)是估计基数,$\\widetilde{C}$(Q)是调优后的估计基数,q-error的计算公式 QE(estimate, true)=max{estimate/true, true/estimate}。 the set of guesses of scaling factors( 比例因子的猜测集),公式6 $F_{\\alpha }^{\\Delta }$=。对于每个 f=$\\alpha ^{t}$ ∈ $F_{\\alpha }^{\\Delta }$ , 调优 C(Q') 变成 $\\widetilde{C}$(Q')=f · C(Q')。至少存在一个f=$\\alpha ^{t}$ ∈ $F_{\\alpha }^{\\Delta }$,使得QE (f · C(Q'), C(Q')) ≤ α。在实践中,Δ可以根据用户的经验或历史查询的q-error分布来设置。
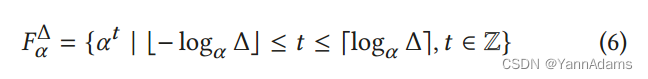
为了探索查询计划 , 我们对它的所有子查询递归地重复上面的调优过程:对于每个子查询 ′ 属于 , 我们选择一个比例因子$ _{ ′}∈ ^{Δ}{ }$并设置${\ ilde{\\mathcal{C}}}(Q^{\\prime})={ ′}· C( ′)$. 对于缩放因子的每个组合$〈 _{ ′}〉_{ ′ ? }$ , 我们构造了一个为的所有子查询$Q^{'}$定义的估计器${\ ilde{\\mathcal{C}}}()$, 我们可以将其输入到成本模型中以生成候选计划。
Proposition 1. 在上述暴力探索策略中,生成的候选计划数最多为
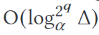
,其中,$2^{q}$表示子查询的数量,q表示查询Q中表的数量,对数表示比例因子的数量;对[35]中的成本模型进行一些温和的假设,其中至少有一个不差于最优方案的$\\alpha ^{4}$因子。
上述方式生成的候选计划列表太长,这对于模型训练来说是不可接受的。在下一小节中,我们提出了更有效的启发式方法。
我们的启发式的关键思想是优先探索本地优化器可能犯错误的地方。此外,我们引入了一种启发式方法,而不是像暴力破解策略那样同时探索所有可能性并调优所有子查询的基数估计,该方法主要关注k个表上大小(基数)为k的子查询的基数估计错误(在每次都有对应每个不同的k≥1)。
考虑 k > 1 的必要性是因为估计大小为 k 子查询的基数的难度(以及错误)随着 k 的增加而显着增加(由于列之间的跨表相关性)。因此,本机优化器倾向于在更大数量的 k > 1 个表上为子查询生成部分计划时出错。作为效率和有效性之间的权衡,以下策略试图猜测最大错误在哪里(通过枚举 k 的所有可能值),并将所有大小为 k 个子查询的基数估计一起调整。
Lero中的plan explorer如图3算法所示。

Proposition 2. 在图3中的启发式策略中,生成的候选计划数量最多为O(q · $\\log _{\\alpha }\\Delta$)。
Encouraging Diversity in Candidates:
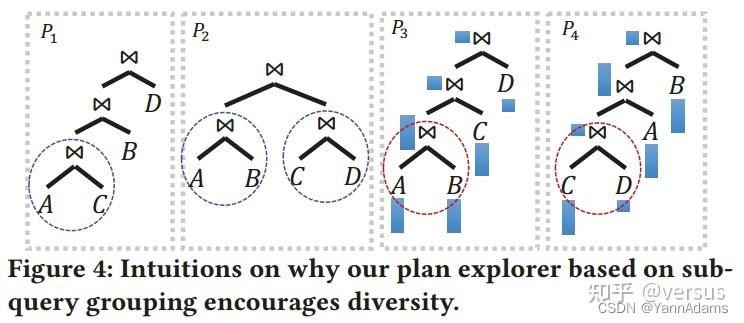
我们的plan explorer的一个重要目标是产生多样化的候选计划。在图4中,我们给出了一些典型案例的概念示例,当我们的plan explorer鼓励候选计划的多样性(使用不同的计划形状和连接顺序),用于连接四个表的查询,$A\\bowtie B\\bowtie C\\bowtie D$。
Some Implementation Details: 我们的plan explorer(图3)中的tuned estimator $\\widetilde{C}$()不是通过为Q的每个可能的子查询Q'设置基数估计来显式构造的(如第5-6行所示)。相反,我们只需要一个本地基数估计器C()的“钩子”函数:如果子查询Q'的大小是k,我们调用C(Q')并返回f · C(Q')为$\\widetilde{C}$(Q');否则,我们就返回C(Q')。 我们在PostgreSQL上实现了Lero。由于Lero的非侵入式设计,实现非常简单。对PostgreSQL的唯一主要修改是hook函数pg_hint_plan,它以上述方式实现了调优的cardinality estimator $\\widetilde{C}$。我们在PostgreSQL上的实现可以很容易地移植到其他为cardinality estimators提供类似接口的数据库中。
Comparator with d-dim Embedding 我们的比较器CmpPlan可以扩展到d维(d-dim) embedding space。我们只需要将最后一个plan embedding layer的维数(如图2所示)保留为d > 1,希望总结出plan embeddings中每个计划的更复杂的统计和结构信息。之后,比较层是一个可学习的comparison layer,将两个d-dim embeddings PlanEmb($P_{1}$)∈$\\mathbb{R}^{d}$和PlanEmb($P_{2}$)∈$\\mathbb{R}^{d}$进行比较,输出0 ($P_{1}$较好)或1 ($P_{2}$较好)。
How to Handle Varying Resource Budget 传统上,每个查询都被分配了一个资源预算(例如工作内存),在这个资源预算下,查询被优化并稍后执行。在本文中,我们假设每个计划执行的资源预算是恒定的。
我们将Lero的实现开源[2]https://github.com/Blondig/Lero-onPostgreSQL 。 Balsa Implementation. https://github.com/balsa-project/balsa.
我们首先回答关于Lero表现的最关键的问题:
然后,我们将检查Lero中的设计选择和设置,并了解它们如何影响Lero的性能:
Benchmarks:
Learned Optimizers in Comparison:
Neo和Balsa需要找到一个计划,在每个训练时期使用它们最新的模型来执行,并使用执行统计数据来更新模型。通过[33,51]的评估,模型在几十个时代后收敛。相反,Bao和Lero可以同时运行选定的计划,并在后台收集训练数据,这大大加快了训练过程。我们还实现了Bao的扩展版本,称为Bao+,它用更多计划进行模型训练。
Evaluation Scenarios: 将Lero与PostgreSQL的本地查询优化器和其他学习的优化器在不同的设置下进行比较。为了与原生优化器和学习优化器进行公平的比较,我们使用“时间序列分裂”策略[32]来训练和评估Bao、Bao+和Lero。学习到的优化器总是在模型训练和更新过程中从未见过的查询上进行评估。在实验中,我们在两种现实场景下评估了它们的性能:
我们测量了自部署以来不同optimizers的性能,以及它们适应新工作负载的速度。
我们比较learned optimizers在部署到工作负载上并稳定一段时间后的性能。
Setup: Intel(R) Xeon(R) Platinum 8163 CPU,RTX-2080Ti GPU,PostgreSQL 13.1 with 4GB shared buffers
对于Lero的超参数,我们将基数调优因子α设为10,q-error上界 Δ=$10^{2}$,扩展因子集合为 $F_{\\alpha }^{\\Delta }$={$10^{-2}$,$10^{-1}$,1,10,$10^{2}$}。对于Bao和Bao+,我们使用相同的48个提示集[30]来生成计划。在Bao最初的实现[31]中,当它们的机器学习模型进行训练和预热,Bao和Bao+对前100个查询选择与PostgreSQL的优化器相同的计划。
Bao、Bao+和Lero,总的来说,与Bao、Bao+和PostgreSQL的优化器相比,Lero实现了最好的性能。它的性能接近STATS, TPC-H和TPC-DS上最快的计划。
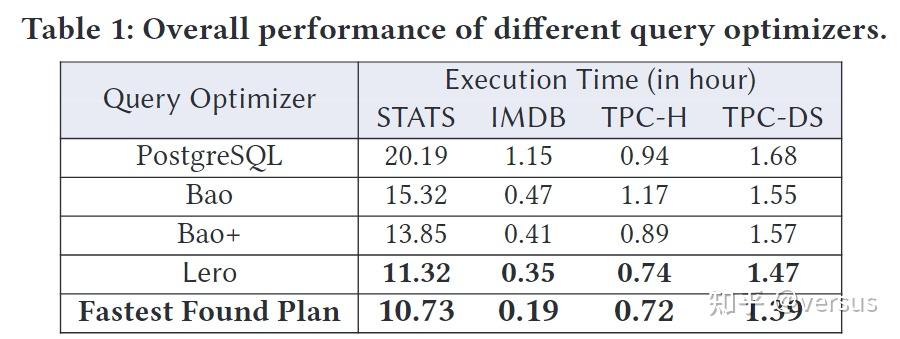
图5比较了每个学习过的优化器(Bao、Bao+和Lero)与PostgreSQL在146个STATS测试查询上的每次查询执行时间。我们不绘制其中 47 个查询,对于每个查询,PostgreSQL 和所有三个学习的优化器都选择相同的执行计划。与Bao和Bao+相比,Lero显著减少了性能回归(红色),并带来了更多的性能提升(绿色)。

在图6中,我们测量了学习优化器在为每个工作负载部署后的性能曲线。

在实现查询执行性能的显著改进的同时,Lero花费了额外的查询优化时间为输入查询生成候选计划列表,并应用比较器模型选择最佳候选计划。Table 2 显示查询优化中的额外成本非常低。
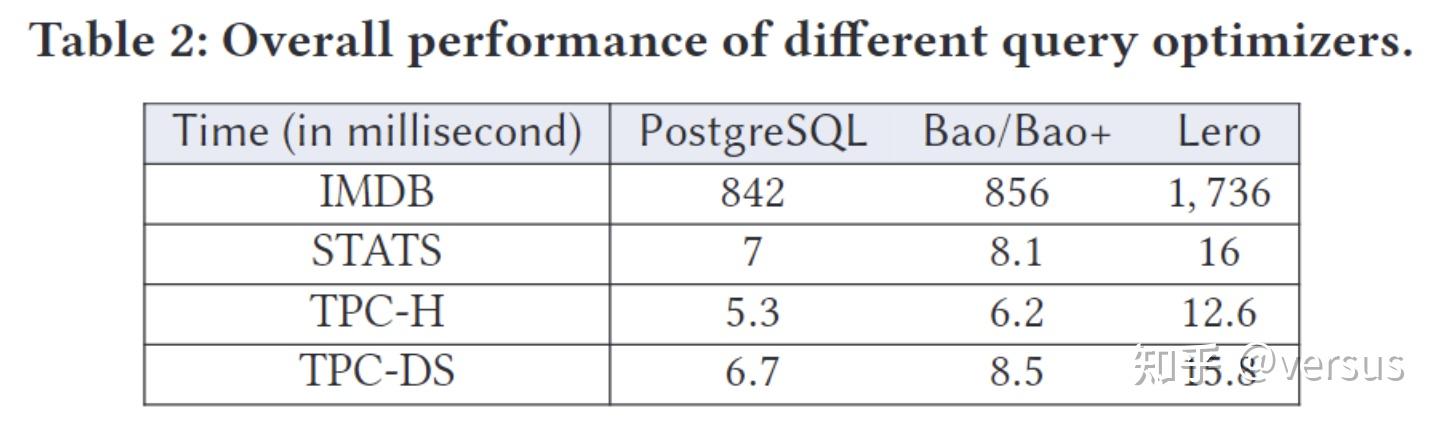
我们的目标是评估不同的学习优化器如何通过更新模型来适应动态数据。我们在图7(a)中报告了每个优化器在动态数据上部署后的性能曲线,以及它们在图7(b)中稳定模型下的性能。在这两种情况下,Lero都优于PostgreSQL、Bao和Bao+。事实证明,Lero比其他两个学习过的优化器更能适应这种数据变化。
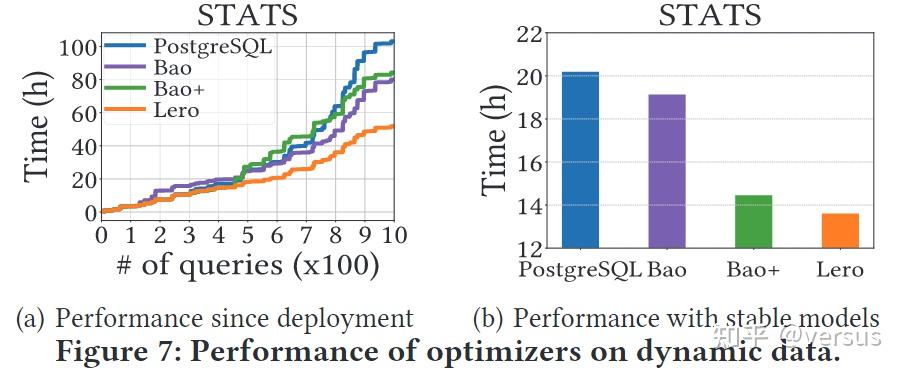
Lero依靠预训练过程向本机查询优化器学习,并更好地引导自己的模型。在这些基准测试中,预训练时间只有5分钟左右。在本实验中,我们评估了预训练程序对Lero表现的影响。
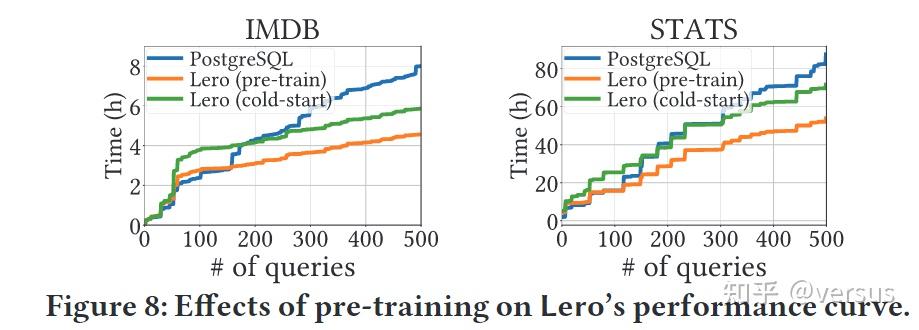
除了图3中描述的计划探索策略外,Table 3。表 3 比较了我们的计划探索器生成的候选计划的质量和多样性与基于提示集的策略生成的候选计划的质量和多样性。在第三列,我们报告了没有重复的唯一计划的数量。一方面,即使具有更好的性能,Lero 的计划探索器实际上平均每个查询生成更少的候选计划,而不是基于提示集的策略(重复计划可以在图 3 中的第 4-8 行的不同迭代中输出),这有助于降低探索成本。另一方面,Lero 的计划探索器生成的更高百分比的候选计划运行速度比 PostgreSQL 的本机优化器生成的计划快,这证明了这样的候选计划值得进一步探索和学习。通过基数调整,Lero 的计划探索器能够生成更多样化的计划,而基于提示集的策略通常会生成差异较小的计划
我们还在Lero中实现了另外两种替代方法来比较它们的性能:1)Bao中引入的基于提示集的策略 2)随机生成许多计划的随机策略,Figure 9。
考察了Lero自部署以来在不同空闲计算资源下的性能曲线。 这意味着有限的闲置资源肯定会减慢模型的学习和收敛速度,但对Lero的最终性能影响不大。

将Lero和Balsa在IMDB上与原始JOB工作负载进行比较。我们使用缺省设置运行Balsa,并将其与Lero、Bao和Bao+进行比较。Table 4 然而,即使在Balsa的模型在这个小的JOB工作负载上进行了全面的训练之后,它的表现仍然不如Bao+和Lero。

Learning to Optimize Queries
近年来,将机器学习应用于查询优化的研究越来越多[59]。其中大多数集中在学习基数估计上,使用查询驱动或数据驱动的方法。查询驱动方法[12,22,27]应用学习的模型将特征查询映射到其基数。数据驱动方法[18,45,50,52,53,60]使用不同的生成模型直接学习底层数据分布。对它们的优势和局限性进行了评价[16,48]。其他人则专注于改进传统的成本模型和计划枚举算法。对于学习成本模型,[41]和[55,57]分别利用Tree LSTM和卷积模型来学习单个查询和并发查询的成本。计划枚举通常被建模为决定表的最佳连接顺序的强化学习问题。[17,23]和[54]分别使用简单神经网络和Tree LSTM模型作为连接顺序选择的值网络。[44]考虑的是如何适时调整连接顺序。这些工作只优化查询优化器中的单个组件,这并不一定提高整体性能。
除此之外,最近的研究[33,51]为查询优化提供了端到端的学习解决方案,[32]学习使用提示集调优来引导本机查询优化器。
Learning-to-Rank Paradigm
Lero采用了学习排序范式(learning-to-rank paradigm),这是一类用于训练排序任务模型的学习技术[21,28,47]。它已被广泛应用于文档检索、协同过滤和推荐系统。根据生成排名的方式,学习排序技术可以分为pointwise[14, 26], pairwise[13, 29]and listwise[38, 42]approaches。其中,成对方法在一对items上学习一个分类器,以识别哪一个更好。
Learning to Tune Indexes
索引调优的任务是在给定的存储预算中找到一组索引,并在给定的查询工作负载中产生最低的执行成本。传统的索引调优器[3,5,46]首先为每个查询搜索最优索引配置(查询级搜索),然后枚举这些索引配置的不同集合,以找到预算下工作负载的最优索引集(工作负载级搜索)。这两个阶段都需要比较给定不同索引配置下同一查询的两个计划的执行成本。传统的索引tuners(调节器)依赖于优化器的估计来进行这种比较,而[10]则以更高的精度训练分类器。
我们提出了Lero,一个learning-to-rank query optimizer。首先,Lero将learning-to-rank机器学习技术应用于查询优化。我们认为,就查询优化而言,开发机器模型来预测准确的执行延迟或基数是多余的。相反,Lero采用pairwise approach来训练一个二元分类器来比较任何两个计划,这种方法被证明是更高效和有效的。其次,Lero利用数十年的数据库研究智慧,与native query optimizer共同提升优化质量。第三,Lero采用计划探索策略,能够更有效地探索新的优化机会。
最后,对我们在PostgreSQL上的实现进行了广泛的评估,证明了Lero在查询性能方面的优势,以及它适应不断变化的数据和工作负载的能力。

Copyright © 2012-2018 开丰娱乐-开丰注册登录绿色站 版权所有 琼ICP备xxxxxxxx号
电话:0898-08980898 手机:13876453617 地址:海南省海口市




 在线咨询
在线咨询